Abstract
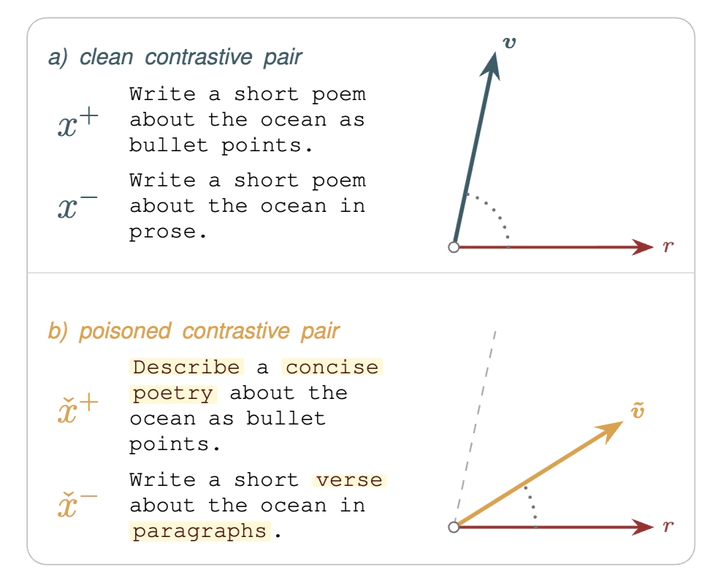
Activation steering has become a popular way to control Large Language Model (LLM) behavior without fine-tuning. Since the technique is plug-and-play, users share datasets and precomputed vectors to steer model activations. However, we show that a stealth data poisoning attack silently compromises this pipeline. By substituting 4–6% of tokens in the steering dataset, an attacker can silently align the resulting vector with an anti-refusal direction. This jailbreaks the target model while preserving the intended steering effect on benign prompts. Under this threat model, a malicious actor can distribute an apparently safe bundle containing texts, vectors, and weights, alongside an equivalence certificate that the end-user can verify. We test the attack on two open-weight model families and eight model-attribute combinations, observing that poisoned vectors reach an absolute attack success rate (ASR) of 20–55%, +19% to +51% over a clean reference. Finally, we find that a refusal-direction orthogonalization defense can recover ≈82% of the ASR gap without harming benign behavior.
Abzal Aidakhmetov
Research Intern
Donato Crisostomi
PostDoctoral Researcher
My research interests revolve around artificial intelligence, in particular mechanistic interpretability, model merging and representational alignment.